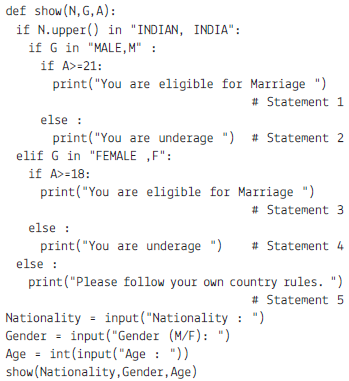
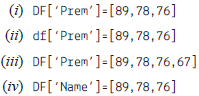
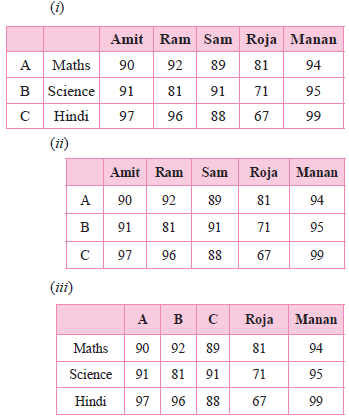
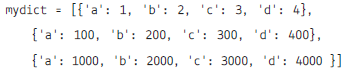Choose the correct option.
(a) What is String data-type in Python?
(i)It is written in double quotes only.
(ii)Its value can be changed.
(iii)It is enclosed in square brackets.
(iv)It is immutable data-type.
(b) Ms. Ragini is confused on the way to compare the strings. Help her in choosing the correct statement.
(i)equal() (ii)equals() (iii) == (iv)compare()
(c) Tejas is confused in the output of the following code. Help him to choose the correct option.
age = 12
txt = "My name is Tejas, I am " , age
print(txt)
(i)('My name is Tejas, I am ', 12)
(ii)My name is Tejas, and I am 12
(iii)(My name is Tejas, I am , 12)
(iv)[My name is Tejas, I am , 12]
(d) Help mini to choose the correct output of the following Python code.
rollno = 3
name = "Mini"
Average = 88.76
Txt = "My name is {1}, having roll no {0} and scored {2} percent."
print(Txt.format(rollno, name, Average))
(i)My name is ‘Mini’, having roll no 3 and scored 88.76 percent.
(ii)My name is Mini, having roll no 3 and scored 88.76 percent.
(iii)‘My name is Mini, having roll no 3 and scored 88.76 percent.’
(iv)(My name is Mini, having roll no 3 and scored 88.76 percent.)
(e) Help Gurnika to choose the correct option for the following Python code.
b = "Hello, World!"
print(b[-5:2])
(i)Hello, World! (ii)orl (iii) Error (iv) No Output