Question
Write SQL commands for the following queries based on the relation Teacher given below:
Table: Teacher
| No | Name | Age | Department | Date_of_join | Salary | Sex |
| 1 | Jugal | 34 | Computer | 10/01/97 | 12000 | M |
| 2 | Sharmila | 31 | History | 24/03/98 | 20000 | F |
| 3 | Sandeep | 32 | Maths | 12/12/96 | 30000 | M |
| 4 | Sangeeta | 35 | History | 01/07/99 | 40000 | F |
| 5 | Rakesh | 42 | Maths | 05/09/97 | 25000 | M |
| 6 | Shyam | 50 | History | 27/06/98 | 30000 | M |
| 7 | Shiv Om | 44 | Computer | 25/02/97 | 21000 | M |
| 8 | Shalakha | 33 | Maths | 31/07/97 | 20000 | F |
(a) To show all information about the teacher of Computer department.
(b) To list the names of female teachers who are in Maths department.
(c) To list the names of all teachers with their date of joining in ascending order.
(d) To display teacher’s name, salary, age for male teachers only.
(e) To count the number of teachers with Age>23.
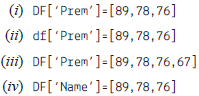
 Choose the output on the basis of the above code.
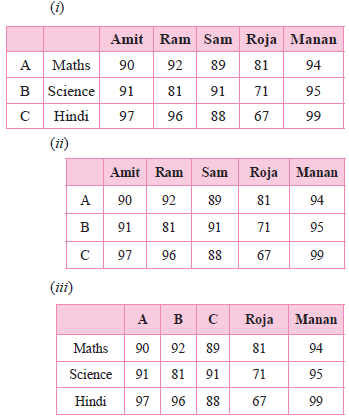
Choose the output on the basis of the above code.