Question 14 Marks
(i) Write the name of the disease occurring as a result of point mutation.
(ii) Explain the lac operon.
(iii) Draw a labelled diagram of the lac operon.
(ii) Explain the lac operon.
(iii) Draw a labelled diagram of the lac operon.
Answer
View full question & answer→(i) The name of the disease occurring as a result of point mutation is Sickle Cell Anaemia.
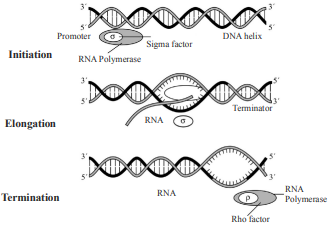
(ii) Lac Operon : It was Jacob and Monod who gave complete elucidation of the Lac operon.
In Lac operon (here lac means lactose) A polycistronic structural gene is regulated by a common promoted and regulator genes. This type of arrangement is very common in bacteria and is known as operon. For example : val-operon, trp-operon, hisoperon, ara-operon etc.
E. Coli bacteria inhabiting in human's intestine derives energy by catabolism of lactose. Jacob and Monod reported that it has a group of three genes in it's DNA which are associated with the synthesis of three enzymes needed for lactose catabolism.
When lactose is present in medium these genes become active but become inactive in absence of lactose Jacob and Monod proposed the operon concept for regulation of these genes activity.
According to this concept, the regulation of gene activity is made at transcription level by induction or repression.
Three enzymes are needed for catabolism and energy production from lactose. These enzymes are
(i) $\beta$galactosidase,
(ii) Permease,
(iii) Transacetylase.
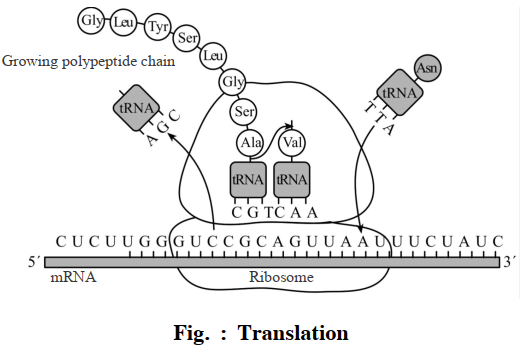
These enzymes are synthesized from translation of poly cistronic m-RNA. The synthesis of this polycistronic mRNA takes place by transcription of three structural genes located in lac operon.
These structural genes or cistrons are—(i) Cis-Z, (ii) Cis-Y and (iii) Cis-A. These are placed adjacently and are mutually coordinated. The activity of structural genes are controlled by regulator gene, operator gene and promoter gene. Cis Z codes for $\beta$ galactosidase which hydrolyses the lactose sugar into glucose and galactose. Cis-Y, codes for permease that increases the permeability of cell for $\beta$ galactosidase. Cis A codes for transacetylase. Therefore the product of all three genes are essential for metabolism of lactose in lac operon.
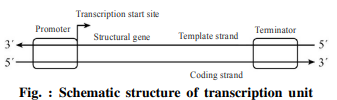
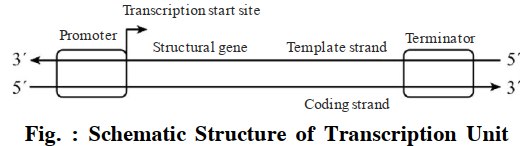
(iii) Labelled Diagram of the lac operon :
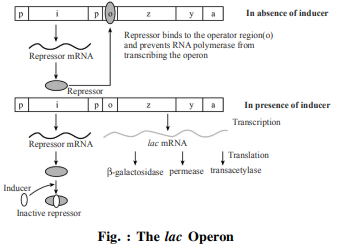
(ii) Lac Operon : It was Jacob and Monod who gave complete elucidation of the Lac operon.
In Lac operon (here lac means lactose) A polycistronic structural gene is regulated by a common promoted and regulator genes. This type of arrangement is very common in bacteria and is known as operon. For example : val-operon, trp-operon, hisoperon, ara-operon etc.
E. Coli bacteria inhabiting in human's intestine derives energy by catabolism of lactose. Jacob and Monod reported that it has a group of three genes in it's DNA which are associated with the synthesis of three enzymes needed for lactose catabolism.
When lactose is present in medium these genes become active but become inactive in absence of lactose Jacob and Monod proposed the operon concept for regulation of these genes activity.
According to this concept, the regulation of gene activity is made at transcription level by induction or repression.
Three enzymes are needed for catabolism and energy production from lactose. These enzymes are
(i) $\beta$galactosidase,
(ii) Permease,
(iii) Transacetylase.
These enzymes are synthesized from translation of poly cistronic m-RNA. The synthesis of this polycistronic mRNA takes place by transcription of three structural genes located in lac operon.
These structural genes or cistrons are—(i) Cis-Z, (ii) Cis-Y and (iii) Cis-A. These are placed adjacently and are mutually coordinated. The activity of structural genes are controlled by regulator gene, operator gene and promoter gene. Cis Z codes for $\beta$ galactosidase which hydrolyses the lactose sugar into glucose and galactose. Cis-Y, codes for permease that increases the permeability of cell for $\beta$ galactosidase. Cis A codes for transacetylase. Therefore the product of all three genes are essential for metabolism of lactose in lac operon.
(iii) Labelled Diagram of the lac operon :